April 27, 2026
MathDuels: a self-play benchmark for mathematical reasoning
MathDuels is a benchmark for mathematical reasoning that does not saturate. Each frontier model both solves problems written by other models and authors problems for them in return, so the difficulty of the test rises with the strength of the field. Two ratings, Solve and Author, are computed from these roles.
This is a short note on MathDuels, a recent benchmark for mathematical reasoning in language models. The work is by researchers including members of our team. The setup differs from a standard benchmark in one specific way: each model is evaluated both as a solver of problems and as an author of problems for others to solve. Two roles, and so two ratings per model.
Background
The standard way to benchmark mathematical reasoning is to fix a set of problems and score every model against it. This works well at first, but it has known limitations. As frontier models approach the ceiling of any fixed test, differences between the top performers shrink to within measurement noise. As a benchmark circulates, its problems tend to leak into training data. And there is the more basic point that solving a problem is not the only thing worth asking of a model, even within mathematics.
Two ratings: solve and author
Each model is asked to do two things. First, solve problems authored by the other models. Second, author problems for the other models to solve. Two ratings are computed from these activities:
- Solve Rating: how well a model solves problems written by other models.
- Author Rating: how difficult a model's authored problems are for the rest of the field.
The two ratings are correlated, but only loosely. Strong solvers are not always the strongest authors, and vice versa.
In mathematics, posing a hard problem is sometimes a more demanding test than solving one. Knowing what to ask, what is known, what is open, and what would be hard rather than merely tedious, is a reasoning skill of its own, and not always the same as the skill of executing a proof. The Author Rating is an attempt to measure something of that skill.
Where the two ratings disagree, the gap carries information that a single solving score does not.
Methodology
The setup is the following. A pool of frontier models generates problems. An independent verifier filters problems that are invalid or ambiguous. The remaining solve outcomes are fit to a Rasch model, a standard tool from psychometrics that jointly estimates a latent ability for each model and a latent difficulty for each problem. Ratings are reported on an Elo-style scale for ease of interpretation.
Results
The main result is read off the joint plot of Solve and Author ratings. If solving and authoring were essentially the same thing, that is, two ways of measuring one underlying ability, then the cloud of points would line up close to a single diagonal. The cloud one actually sees is broader than that. Several models sit notably higher on Author Rating than on Solve, and several others the reverse.
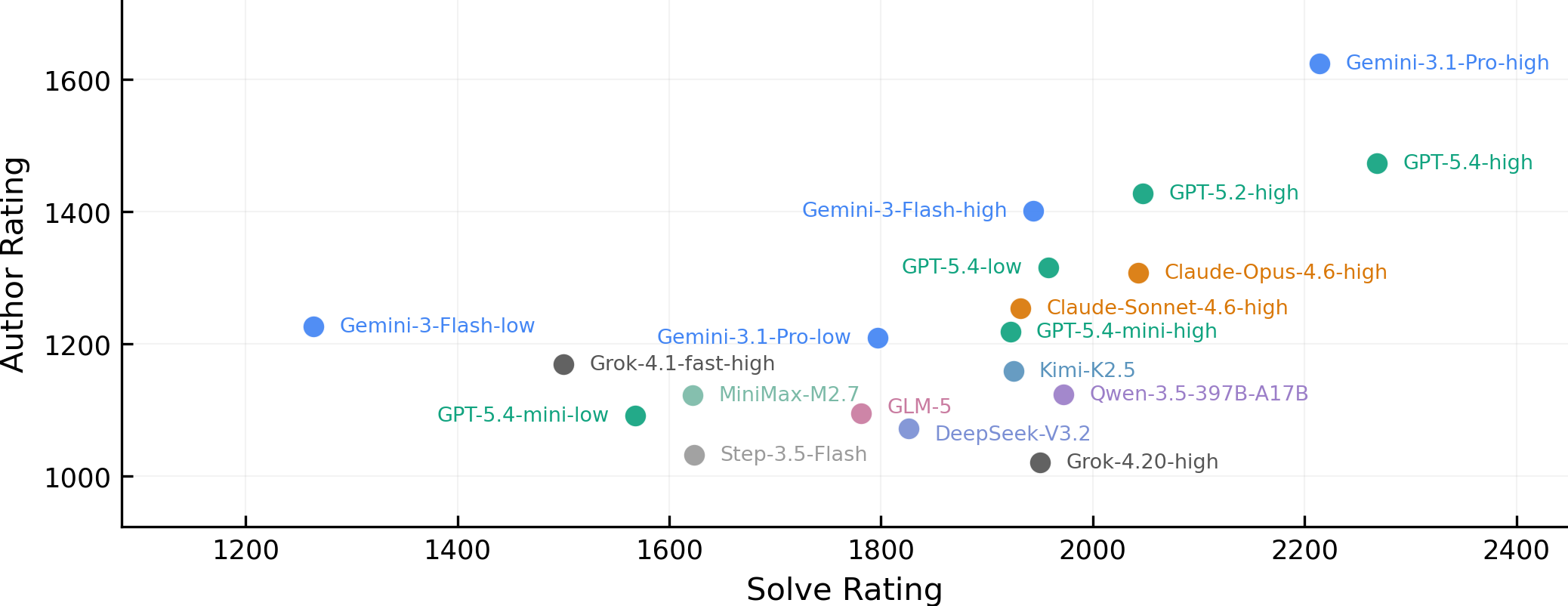
A second observation concerns thinking effort. When a model is configured to spend less reasoning per problem, its Solve Rating tends to drop more than its Author Rating. The effect is modest in any single case but consistent across the field. So authoring, on this evidence, is at least partly separate from solving.
The current standings, model by model, are kept up to date on the leaderboard at mathduels.ai.
Two problems
For concreteness, here are two problems from the benchmark, one from a strong author and one from a weak author. The stronger author writes a problem whose difficulty lies in uncovering the right group-theoretic structure; the weaker author asks for a straightforward execution of standard cyclotomic degree formulas.
Strong author
Gemini-3.1-Pro-high · Author rating 1624 · solve rate 8/19
Find the total number of isomorphism classes of groups G of order 2024 such that every element of G of odd order belongs to the commutator subgroup G′.
Answer: 15. The hypothesis forces the abelianization G/G′ to be a 2-group, after which one has to classify the possible group structures compatible with that restriction.
Weak author
Grok-4.20-high · Author rating 1020 · solve rate 19/19
Let ζ be a primitive 91st root of unity. Compute [ℚ(ζ13 + ζ−13, ζ7 + ζ−7) : ℚ].
Answer: 18. Degrees of the real subfields are φ(7)/2 = 3 and φ(13)/2 = 6; coprimality gives the compositum degree by direct multiplication.
The contrast is what the Author Rating is designed to detect.
A self-renewing benchmark
One feature of this kind of setup is that it does not exhaust as easily as a fixed benchmark. The problems are written by the participating models, so the benchmark's difficulty co-evolves with the field. As stronger models join, they raise the bar for everyone. The hope is that the comparison stays informative as the frontier moves forward.
Resources
The leaderboard is at mathduels.ai. The full paper is on arXiv. Researchers interested in adding a model to the leaderboard may write to oscar@rabdos.ai.
Research from our team